The tools on this page are programs I have developed for various language analysis or annotation purposes over a number of years. They are freely usable for non-commercial purposes under GPL 3.0 licence.
Upon request by some colleagues, I’ve recently also created 32bit versions for most programs. These will run on older Windows versions, can easily be carried on a memory stick to be used on any Windows computer, and also be run on Mac OS X and Linux using Wine. As 64bit computers are more and more becoming the norm, though, I’ll only produce 32bit versions on special request from now on (Fri May 03 14:30:15 2019), though.
This page will be expanded, e.g. by adding more tools and more extensive descriptions, in due course. Please report any bugs you might identify to me, so I can fix them and make the programs more useful/useable. Also feel free to email me suggestions for improvement or additional features. Please note, though, that I’m currently ‘transitioning’ my programs from Perl & Perl/Tk to Python & PyQt, so that I will probably not make any major changes in the foreseeable future.
‘Installation’ Instructions
My tools generally don’t require any installation, but I sometimes provide installers for the sake of convenience for users less experienced with extracting from zip archives. The main advantage in extracting from zip files, though, is that you should also be able to run the programs from a memory stick without installation.
As most programs are designed to allow more experienced users to change/customise the configuration files or to store associated data in a ‘data’ folder within the same folder the tool resides in, you should always extract all files from the zip archive to a location where you have write-access. This should generally not be the ‘Program files’ folder, because that folder restricts write access, but instead a folder like ‘C:\<toolname>’, where <toolname> is the name of the respective tool, ideally without spaces. For frequent use, you may also wish to set up a shortcut to the executable on your desktop. This can normally be achieved by right-clicking the executable in your file manager, holding and dragging it to the desktop, and then, after releasing the right mouse button, selecting ‘Create shortcut here’.
I’ve recently also noticed that installation to a folder containing Chinese or other ‘non-English’ characters appears to cause issues in some programs finding the configuration files, etc. If you encounter such a problem, please move the program files to a folder that only contains basic Latin characters.
The Dialogue Annotation and Research Tool (DART; Ver. 3.0)
Thu May 30 11:36:06 2019: Version 3.0.1 released.
The Dialogue Annotation and Research Tool is an annotation tool and linguistic research environment that not only makes it possible to annotate large numbers of dialogues automatically, but also provides facilities for pre- and post-editing dialogue data, as well as conducting different types of analysis on annotated and un-annotated data in order to improve the annotation process. To decide whether DART may be interesting/useful for you, you can first take a look at the DART Manual. The new version now identifies 162 speech acts automatically, and also has a number of additional functions and improvements to both the interface and the output options from within the individual analysis modules, as well as a completely new pattern counting facility.
A PDF that contains the current speech-act taxonomy used in/by DART is available from here.
To ‘install’, just extract all files to a folder where you have write access, ideally ‘C:\DART’ or something similar. You can then start the program by running dart.exe. Along with the program and its resource files, a complete non-annotated version of the SPAADIA corpus (see below) is provided in the ‘spaadia’ folder for practice, so that you can test the annotation feature yourself and see which annotation features may require post-processing.
If you installed version 3 before 30th May 2019, please replace it with version 3.0.1, which contains some minor bug fixes and improvements to some of the resource files.
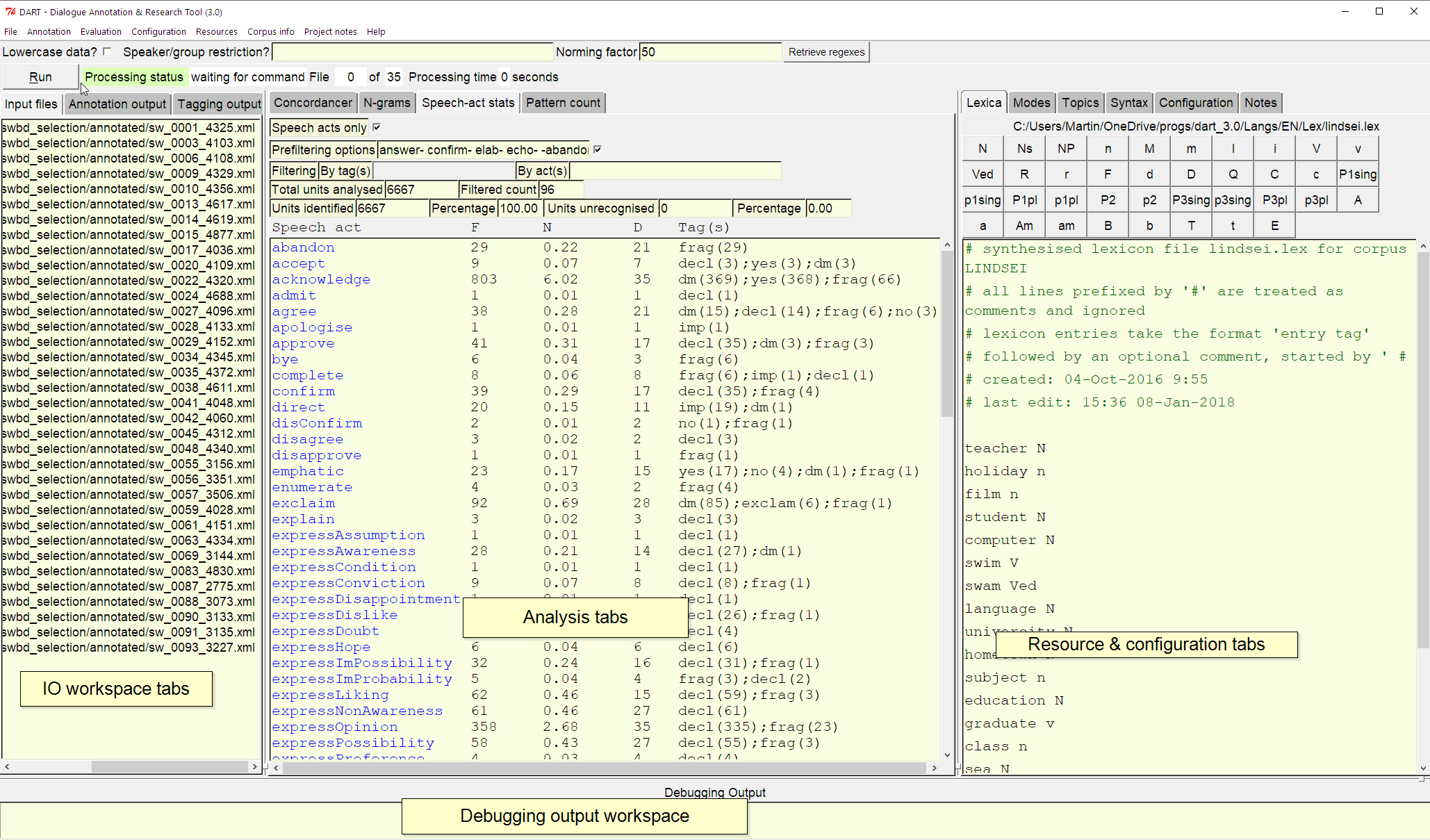
Current version: 3.0
- DART 3.0 (64bit zip archive only). Released 03-May-2019, updated to version 3.0.1 on 30-May-2019.
Older Versions:
- DART 2.0 (64bit zip archive). Released 25-July-2017.
- DART 2.0 (32bit zip archive). Released 25-July-2017.
- DART 1.1 (32bit only zip archive). Released 18-May-2015.
- 64bit Windows setup file, released 05-Mar-2014
- 32bit Windows setup file, released 25-Sep-2014
- 32bit Windows zip archive, released 15-Feb-2015
The Text Annotation and Research Tool (TART; work in progress)
The Text Annotation and Research Tool (TART) will be DART’s written-language counterpart for identifying the equivalent of speech acts in written language. Although I already began developing initial design ideas and a simple prototype based on the DART model a few years ago, and also presented on some of these at CL 2015 in Lancaster, various other commitments have delayed the development so far.
Apart from including very similar annotation and analysis features to DART, TART will also contain features more specifically geared towards written-language analysis, some of which will be derived from the features implemented in the Text Feature Analyser, such as measures of lexical density, various ratios based on different units of analysis (whole texts, paragraphs, sentences, and possibly other types of textual divisions), most of which will be calculable with or without stopwords and including a variable norming factor to facilitate comparison between different texts of unequal length.
One major part of the ongoing development consists in modelling all the relevant necessary features that will enable TART to annotate texts from various different genres/text types, as well as providing different means of analysing or filtering by these specific features.
So far, the main interface has already been ported from DART, and a new XML document category for written-text categories defined (including the levels of text, heading, and paragraph) and integrated into the tool. In addition, a number of routines for some automated pre-processing (paragraph splitting based on major punctuation marks, etc.) have been implemented, and a number of conversion and/or extraction tools for converting data from existing reference corpora have been created to make it possible to test the TART routines using various types of data.
The Simple Corpus Tool (SCT)
The Simple Corpus Tool (Ver. 3): A combination of annotation & analysis tool for use with either simple XML files or basic plain-text files. The new Python version now provides more or less the same functionality as other tools like AntConc or WordSmith, and includes modules for concordancing in both stream (i.e. KWIC) and line-based mode, word & n-gram analysis, keyword/-phrase analysis, collocation analysis, and pattern counting, but no longer provides a PoS tagging option.

Files selected for opening are displayed in the ‘Input Files’ list on the left-hand side of the program. Double-clicking the file name will open the corresponding file in the built-in editor. If a hit is clicked in the ‘Concordancer’ module, this will also open the relevant file in the editor, this time displaying the hit in its full context, but also allowing you to add annotations.
The tabbed pane in the middle contains the individual analysis modules. Unlike other tools, these include a ‘Pattern count’ facility where you can associate regexes with suitable labels for counting patterns in all open files. As its name implies, the ‘Keyphrases’ module not only allows you to look for keywords, but also phrases, based on a weighted relative ratio. All modules, apart from ‘Pattern count’, as well as the SCT itself, can also be easily be configured, and provide various sophisticated filtering options that also allow you to process loaded files without needing to edit the original data.
The built-in editor on the right-hand side allows you to add tags and attributes from user-configurable toolbars and menus. The editor itself is based on the PyQt ‘QTextEdit’ widget, and provides standardised shortcuts for copy & paste and undo/redo functionality as in many standard text editors. It also supports search-and-replace operations that support regexes, thereby making it possible to carry out advanced editing, including conversion to the DART XML format.
The extensive PDF help file is triggered via the relevant menu or pressing F1.
Current versions (v. 3.0)
- Windows (64bit): This Windows version comes with a proper installer. Unfortunately, though, the only way I found to compile it bundles all the relevant Python libraries with it, so that some anti-virus toolkits may report this as a threat that you can safely ignore.
- MacOS:
- Create a folder called ‘SCT’ in your ‘Documents’ folder.
- Download the zip archive SCT3_Mac.zip.
- Copy its contents to the ‘SCT’ folder, unless the file is automatically unzipped there. Sometimes, the folder name may correspond to the name of the zip archive, though, in which case you need to rename that folder to ‘SCT’.
- Launch the SCT. On some MacOS versions, you may get an error message that the file couldn't be verified. If that happens, go to the settings, choose 'Security & Privacy', and unblock the app. On other versions, you may need to use a right mouse click on the app and choose ‘open’ & then confirm once that you want to open the app.
- Run it again.
Older Versions (v. 2.0 released 19-Jun-2018)
- Zip archive (64bit Windows): follow the general ‘installation’ instructions and run ‘SCT64.exe’.
- Zip archive (32bit Windows): as above, but then run ‘SCT32.exe’.
The Web Corpus Compiler (WCC)
A successor to ICEweb (see further below) that allows you to search and download corpus data from the web. This program is much more flexible and easier to use than its predecessor, and also allows you to work with different languages easily. In contrast to ICEweb, it also sports a built-in browser so that you can search, explore, and download conveniently from within the same tool. To get a better idea of its capabilities, you can take a look at the WCC Manual. Unfortunately, though, the manual cannot be opened from within the tool on the Mac, so that you'll need to find it in the application folder and open it manually.

Current versions (v. 1.0)
- Windows (64bit): This Windows version comes with a proper installer. Unfortunately, though, the only way I found to compile it bundles all the relevant Python libraries with it, so that some anti-virus toolkits may report this as a threat that you can safely ignore.
- MacOS:
- Create a folder called ‘WCC’ in your ‘Documents’ folder.
- Download the zip archive WCC_Mac.zip.
- Copy its contents to the ‘WCC’ folder, unless the file is automatically unzipped there. Sometimes, the folder name may correspond to the name of the zip archive, though, in which case you need to rename that folder to ‘WCC’.
- Launch the WCC. On some MacOS versions, you may get an error message that the file couldn't be verified. If that happens, go to the settings, choose 'Security & Privacy', and unblock the app. On other versions, you may need to use a right mouse click on the app and choose ‘open’ & then confirm once that you want to open the app.
- Run it again.
The Tagging Optimiser
The Tagging Optimiser (Ver. 1.0; released 02-Oct-2018) helps corpus users to automatically enhance the tagging accuracy and readbility of output from 3 freeware taggers, the TreeTagger, the Stanford POS Tagger, and the Simple PoS Tagger (see below). It does so by diversifying the original tagset, fixing some of the errors caused by the probabilistic engines underlying the taggers, and making the tags more readable by expanding their names. Details about the tagset can be found in the accompanying manual.

The Tagging Optimiser is available as either a 64- or 32bit program:
To install, simply follow the general ‘installation’ instructions above and run ‘tagOpt64.exe’ or ‘tagOpt32.exe’, respectively.
The Simple PoS Tagger
The Simple PoS Tagger (Ver. 1.0) is an interface to a slightly modified version of the Perl Lingua::EN::Tagger module that allows the user to add morpho-syntactic tags to a text automatically, and then post-edit the colour-coded output. To ‘install’, simply extract the files from the zip archive into a folder you have write-access to and run the executable (‘Tagger.exe’). The interface should be relatively intuitive to use, but some basic usage info is provided under the ‘Help’ menu.

The output in my interface differs slightly from the original version produced by the tagger in that I’ve replaced the originaly slashes that separate words and tags by the more ‘traditional’ underscore format that provides better readability.
For future releases, I’m planning to include some more features that will make it possible to explore the tagged text in various ways, e.g. through switching some of the colour-coding on an off to identify structures like NPs, etc., visually.
Versions:
The SPAADIA concordancer
The SPAADIA concordancer (32bit Windows version): a concordancer (mainly) for use with the SPAADIA corpus (see). Theoretically, the concordancer can handle any plain text-based files, such as .txt, (X)HTML and XML files, though, provided that the right extension is set in the box on the top right-hand side of the interface. The assumed input encoding for files is UTF-8, and the concordancing works best for files where tags and text are separated. The concordancer allows for searches of one or two search strings in combination, using the full set of Perl regular expressions. Any whitespace in an expression needs to be ‘quoted’ via \s and possibly quantified if there may be multiple spaces. Now largely superseded by the above.
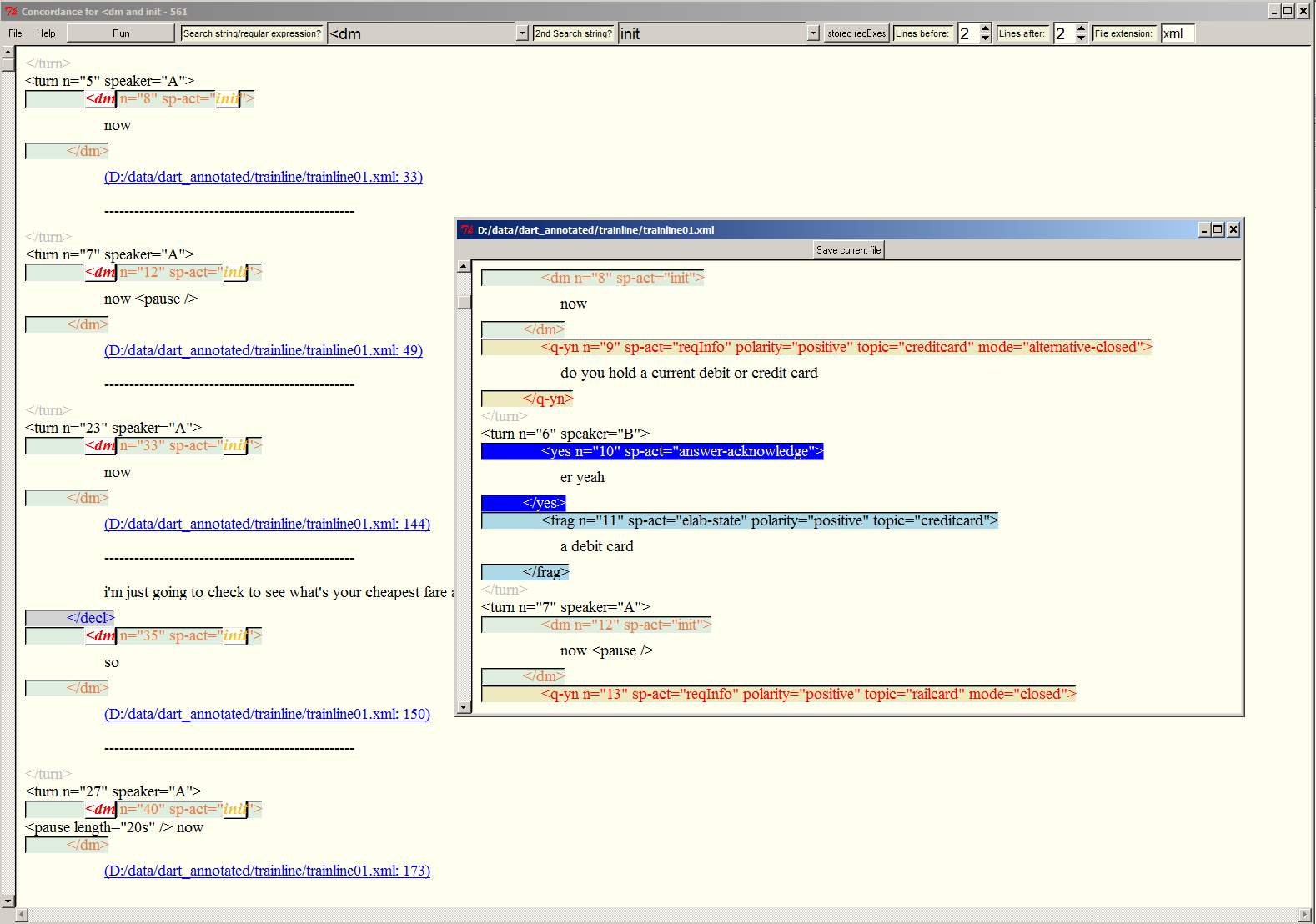
The Text Feature Analyser
The Text Feature Analyser (Ver. 2.1; 64bit Windows only; released 07-May-2014): a tool for investigating textual features that may help in identifying & measuring issues related to text complexity. The basic design and usage are described in my original article on the tool, which can be downloaded from my publications page. Please note that some features discussed in that article, such as the concordancing functionality, have already been added since then.
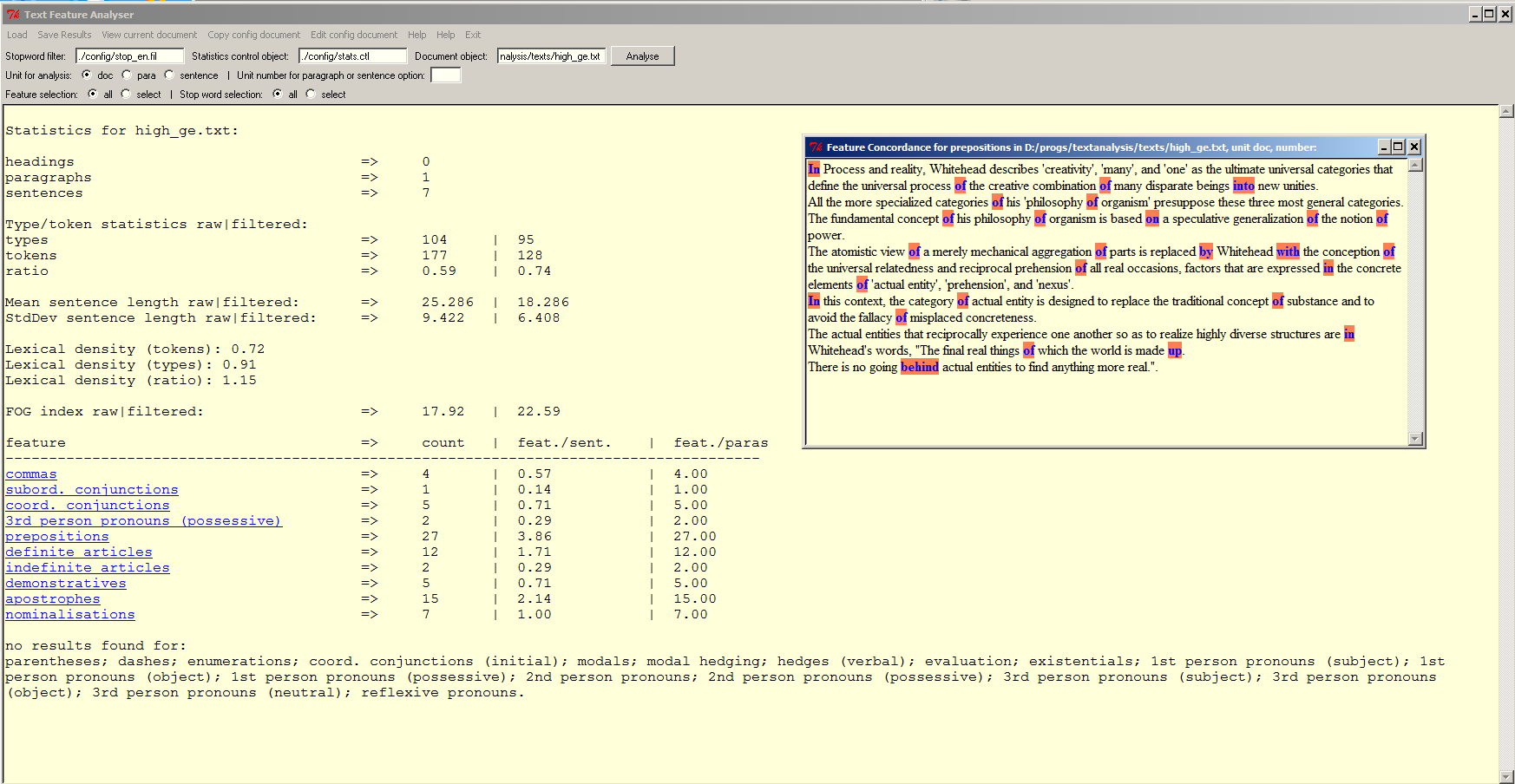
This tool will soon undergo a (major) re-write. The most recent version already contains a bug fix for the syllable count, which had produced some errors in the earlier version, and now also adds output that lists the number of (estimated) syllables in a document. Future versions will not only contain better documentation (which is, admittedly, very sparse at the moment), but probably also a tabbed interface where the analysis for each new document will be listed on a separate tab, etc.
ICEweb
Version 2
ICEWeb is a small & simple utility for compiling & analysing web corpora. The name was chosen because the main intention behind the tool is to allow researchers to augment existing or create new corpora for the International Corpus of English (ICE).
It is designed to be as user-friendly as possible, yet still allows some fairly sophisticated processing, including boiler-plate removal, of whatever web pages are downloaded. For a slightly more comprehensive overview of its features, you can take a look at my ICAME 39 presentation. For detailed information, please consult the ICEweb2 Manual (included in the distribution).
You can download the 64bit version from here. If anyone should really still require a 32bit version, please send me an email, and I’ll compile one and will add it here. To ‘install’, simply follow the ‘installation’ instructions and then run ‘iceWeb2_64bit.exe’.
Fri 06-Mar-2020 09:48:38: Version 2.2 now also allows you to change the language specified when creating queries via the configuration file using the IANA country code.
Please note that there were some bugs in version 2.0, which may have prevented queries from being opened in search engines if you has more than two seed terms & directories for URL files from being created. If you downloaded version 2.0, please replace it with 2.2.
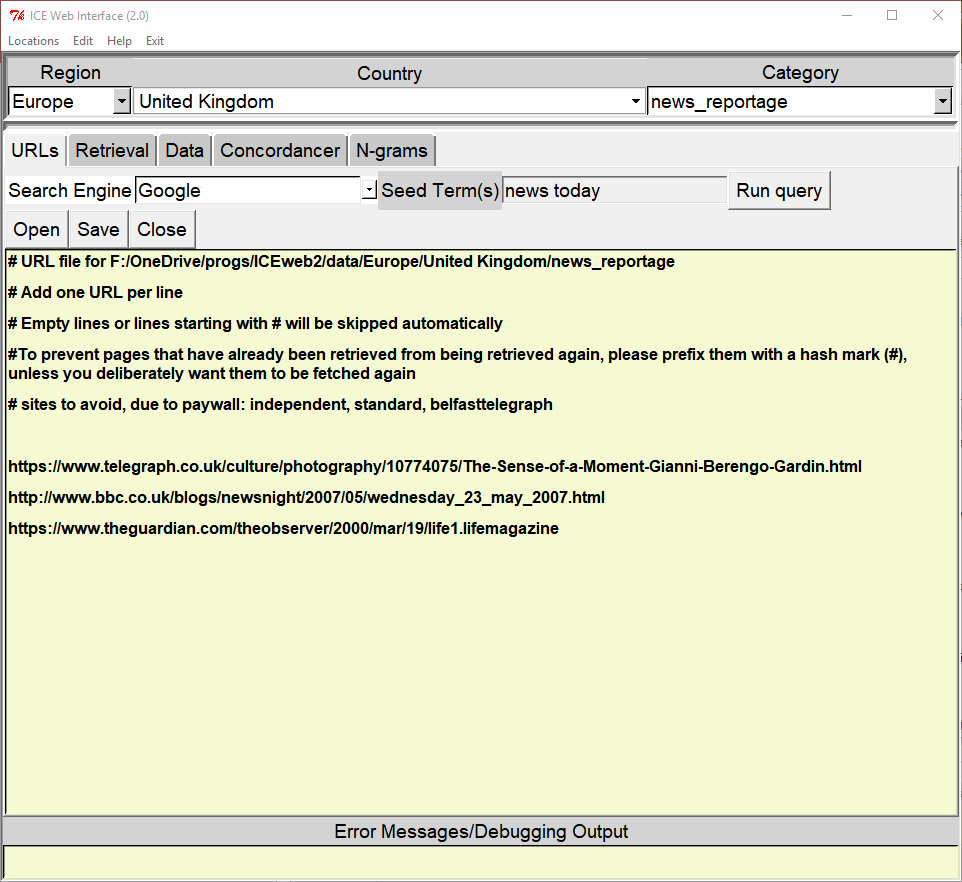
Version 1
Please note that this version has now been superseded by Version 2 above, which has greatly enhanced features. I’m still keeping this version online for the moment, though, as it’s the one described in Section 4.2.4 in my Introduction to Corpus Linguistics textbook, and used for the exercise there.
ICEWeb (Ver. 1; 32bit Windows):
The (Phonetic) Transcription Editor
The (Phonetic) Transcription Editor (32bit Windows version): as the name says, mainly an editor for creating phonetic transcriptions, which allows output to be saved to a UTF-8 encoded text file or (double-spaced) HTML page, suitable for submission of assignments. The program also provides an option for grapheme–to–phoneme conversion, which, however, has some serious limitations, as it ‘knows’ nothing about strong and weak syllables or features of connected speech.
![]()